







Last week we covered the new rendering features found in DirectX 12 along with performance comparisons between DX11 and DX12. Today we will focus on how DirectX 12 allows developers to efficiently utilize GPUs and reduce CPU overhead for better performance. During this year’s GDC, Microsoft’s Bennett Sorbo took centre stage to explain how DirectX 12 is not only a low level access API for a variety of GPU hardware but it also has a very low level of abstraction compared to DX11. Not only that, it also manages to take care of resource management issues such as the order they are going to be used in and how they are going to be used in rendering operations which results into awesome performance gains on the CPU and GPU.
Explicit Resource Transitions

So how can developers gain more from GPU using DirectX 12? Bennett states there are three ways to do that. First approach is called Explicit Resource Transitions. It’s fairly public knowledge that modern GPUs work with resources in the form of states and using these states they have knowledge of where these transitions or instructions needs to occur in the pipeline. For example, if you want to read a texture from a render target, some GPUs will actually compress it and save bandwidth in the process, but if it’s the opposite, it needs to be decompressed into a different hardware state so that other parts of the GPU can read it efficiently. Another important thing that developers need to keep track of is the transitions of resources and make sure that they are in sync with each other.
In DirectX 12, there is actually an in-built application that will notify the GPU about the current state of the resource. For example, the app will tell the GPU that the current state was a render target but now it’s now being used as a shader resource. This lets the developer know when they are asking the GPU to do the work or move from one state to another. Of course this may be happening in DX11 but in an abstract way. This way the developer can minimize the number of redundant state transitions resulting into less unexpected stalls and performance loss.
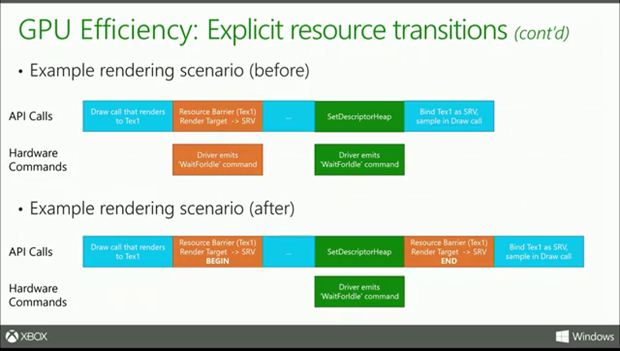
In DX11, whenever a developer wanted to a dispatch call back to back, the API will ensure that all reads and writes will be complete for a given call resulting into some idle time before the next dispatch event happens. Using DirectX 12, the developer is now responsible for telling the app when these idle times are needed. So if your app does not need any stall times, the dispatches can run back to back. What’s more? Multiple dispatches up to hundreds on a modern GPU can be run in parallel followed by idle time (if any).
In order to demonstrate this new feature, check out a head to head comparison between DX11 and DX 12 versions of Fable Legends.
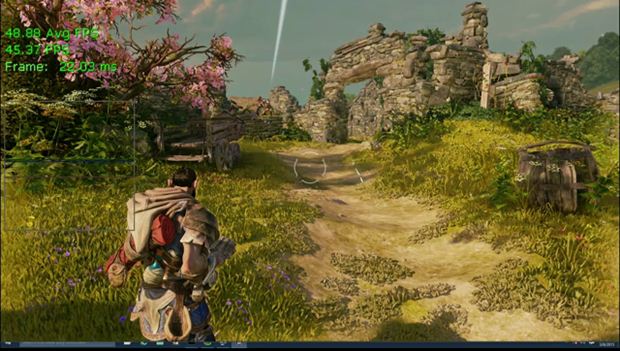
Fable Legends DX11 version: The application does not have upper level knowledge resulting into lower frame rates compared to the DX12 version below.
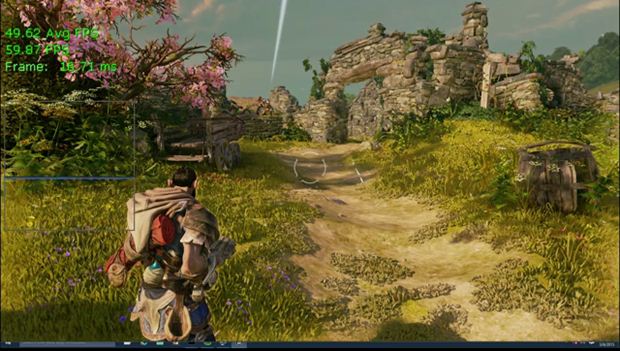
Fable Legends DX12 version: The application has upper level knowledge resulting into higher frame rates due to less GPU idle times/stall.
In our previous article, we briefly talked about ResourceBarrier API that takes care of the GPU hazards. So using this API, the developer can communicate with the GPU about the different states that we talked about earlier in this article. Now consider an example where you want to read a render target for a number of frames. So using DirectX 12, developers can perform these transitions over a long period of time using ResourceBarrier API with the begin and end states with both of them having their individual before and after states. In this way redundant operations are avoided and is ideal for processes where a resource is not going to be used for a long period of time.
Parallel GPU Execution:

Modern GPUs are completely capable of running multiple workloads provided they are not dependent on each other, allowing developers to use the hardware efficiently. In the previous article we briefly touched upon the three engine types which are 3D (which can do whatever operations you want to using DX11 context), compute engine (which can clear queues and perform dispatches) and lastly copy which is used for copy operations. All of these engine types can be used in parallel provided the application has the upper level knowledge what resource the developer is going to use ahead of time.
The copy engine can be used in scenarios where the developer knows that in a few seconds the app will be accessing a particular texture. The copy engine will then stream copies of the texturing using system memory or the GPU memory without blocking the 3D engine. For comparison sake, Bennett showed off the results on the GPU View, a tool that tracks what is happening on the GPU at any moment.
In the image below, the copy and compute operation would normally take more time, in this case 92 milliseconds.
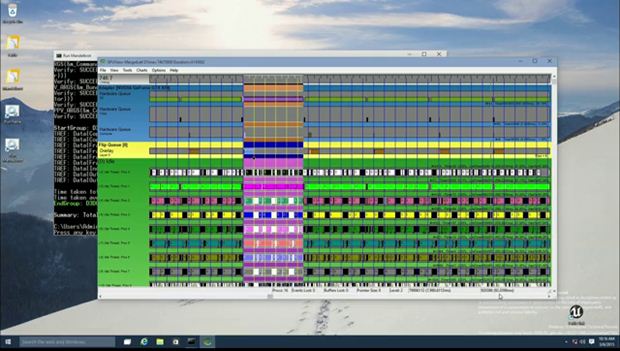
But when the developer uses the copy engine, the hardware is actually executing several command buffers in parallel, avoiding serialization. The 3D work is only 41 ms and the copy work is only 27, and that too parallely.
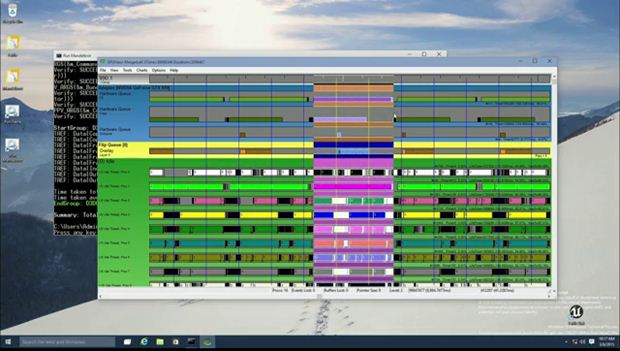
Moving forward. The compute engine is widely used in games, offering unique rendering solutions. If you are doing a long running simulation and if the app needs lesser frames, the GPU can run it on a lower priority by allocating it lesser cycles. But when the developer needs the resource, the 3D queues can be delayed. It can also be used in cases where there are dependencies between the compute and 3D engines for a smaller frame time. For example, if the compute engine is running a bit longer, the developer can actually tell the 3D engine to wait. But again, this depends on what you are doing in the application.
GPU Generated Workloads:
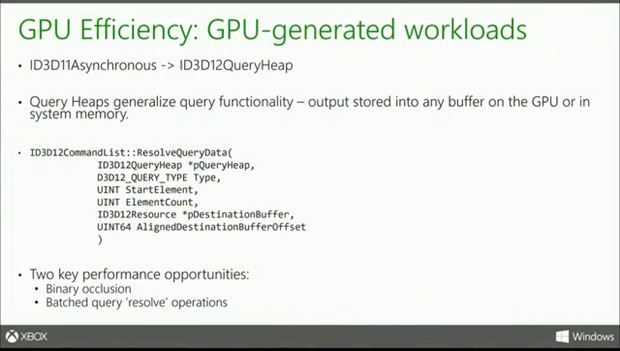
Microsoft have added a lot of new features so that the API is extremely flexible while it’s processing rendering operations. In DX11 each query was treated as independent entity using the ID3D11Asynchronous class allowing the developers to get the data whenever they want. In DirectX 12, the developer retrieves the data in the form of heaps. So one can carry out thousands of queries in a single batch and they can be executed using a single resolve operation. In this way, the GPU does not need to worry about resolving individual GPU operations as it only needs to take care of a batch or a heap now.
CPU Overhead:
One of the first features that was first announced last year was that DX12 reduces CPU overhead by 50%. This is especially critical in cases where a user has a dual GPU configuration and the CPU becomes the eventual bottleneck. Out of the box, DirectX 12 allows no high frequency ref counting, no hazard tracking and and no state shadowing. This means that the API will now manage the lifetime of the resource in the memory. When the developer wants to release it, it will be immediately released. If the developer chooses to bind something as render target, DX12 won’t unbind it unnecessarily compared to the dynamic runtime process in DX11.
CPU overhead can be reduced using Resource Binding, something I have explained in my previous article on DX12. Resource Binding is divided into two processes Descriptor Heap and Root Signature. The descriptor heaps are the actual GPU memory that controls how resources are bind in the pipeline. Unlike DX12, the descriptor heaps are directly exposed to the application itself allowing developers to bind individual resources in an efficient way because the application has a higher level knowledge on how it plans to use its resources. Root Signature is related to the draw function’s arguments which will allow the developers to put the texture bindings in the root signature function itself giving direct access to the relevant resource in the descriptor heap. This is ideal for high frequency updates.
In case of multi threading, DX11 creates a background thread which falls outside the control of the application but in DX12, multi threading is directly controlled by the application itself and each command list is independent and efficient in generating rendering commands. In cases where the developer cannot implement parallelization and has to adopt serialization, DX12 allows the developer to develop a background submission thread depending on the application’s needs.
DX12 also provides new developer tools such as fences which gives an indication on how far the GPU is in execution as well as the ability to develop one large allocation and place resources within it which can then be mapped/unmapped according to the application.
Closing Words:
Using DirectX 12, the developers will have the final word on where and how they want to utilize their resources but eventually they would need to do a lot of work in providing high level information to the application. But there is no doubt that there are some serious performance gains to be had via DirectX 12, at least on the PC.





